响应式编程 Reactor
从响应式编程说起
响应式编程是一种关注于数据流(data streams)和变化传递(propagation of change)的异步编程方式。 这意味着它可以用既有的编程语言表达静态(如数组)或动态(如事件源)的数据流。
在响应式编程方面,微软跨出了第一步,它在 .NET 生态中创建了响应式扩展库(Reactive Extensions library, Rx)。接着 RxJava 在 JVM 上实现了响应式编程。后来,在 JVM 平台出现了一套标准的响应式 编程规范,它定义了一系列标准接口和交互规范。并整合到 Java 9 中(Flow 类)。
响应式编程通常作为面向对象编程中的“观察者模式”(Observer design pattern)的一种扩展。 响应式流(reactive streams)与“迭代子模式”(Iterator design pattern)也有相通之处, 因为其中也有 Iterable-Iterator 这样的对应关系。主要的区别在于,Iterator 是基于 “拉取”(pull)方式的,而响应式流是基于“推送”(push)方式的。
- iterator 是一种“命令式”(imperative)编程范式,即使访问元素的方法是 Iterable 的唯一职责。关键在于,什么时候执行 next() 获取元素取决于开发者。
- 响应式流中,相对应的角色是 Publisher-Subscriber,但是当有新的值到来的时候 ,却反过来由发布者(Publisher) 通知订阅者(Subscriber),这种“推送”模式是响应式的关键
此外,对推送来的数据的操作是通过一种声明式(declaratively)而不是命令式(imperatively)的方式表达的:开发者通过描述“控制流程”来定义对数据流的处理逻辑。
除了数据推送,对错误处理(error handling)和完成(completion)信号的定义也很完善。一个 Publisher 可以推送新的值到它的 Subscriber(调用 onNext 方法), 同样也可以推送错误(调用 onError 方法)和完成(调用 onComplete 方法)信号。 错误和完成信号都可以终止响应式流。可以用下边的表达式描述:
1 | onNext x 0..N [onError | onComplete] |
这种方式非常灵活,无论是有/没有值,还是 n 个值(包括有无限个值的流,比如时钟的持续读秒),都可处理。
以上来自 https://projectreactor.io/docs/core/release/reference/ 翻译
Reactive Streams
Reactive Streams 是上面提到的一套标准的响应式编程规范。它由四个核心概念构成:
- 消息发布者:只有一个 subscribe 接口,是订阅者调用的,用来订阅发布者的消息。发布者在订阅者调用 request 之后把消息 push 给订阅者。
1
2
3public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
} - 订阅者:订阅者包括四个接口,这些接口都由 Publisher 触发调用的。onSubscribe 告诉订阅者订阅成功,并返回了一个 Subscription ;通过 Subscription 订阅者可以告诉发布者发送指定数量的消息(request 完成) ;onNext 是发布者有消息时,调用订阅者这个接口来达到发布消息的目的;onError 通知订阅者,发布者出现了错误;onComplete 通知订阅者消息发送完毕。
1
2
3
4
5
6public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
} - 订阅:包括两个接口,请求 n 个消息和取消此次订阅。
1
2
3
4
5
6
7
8
9public interface Subscription {
// request(n)用来发起请求数据,其中n表示请求数据的数量,它必须大于0,
// 否则会抛出IllegalArgumentException,并触发onError,request的调用会
// 累加,如果没有终止,最后会触发相应次数的onNext方法.
public void request(long n);
// cancel相当于取消订阅,调用之后,后续不会再收到订阅,onError 和
// onComplete也不会被触发
public void cancel();
} - 处理器:Processor 同时继承了 Subscriber 和 Publisher;其代表一个处理阶段。
1
2public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
Reactive Streams 通过上面的四个核心概念和相关的函数,对响应式流进行了一个框架性的约定,它没有具体实现。简单来说,它只提供通用的、合适的解决方案,大家都按照这个规约来实现就好了。
Java 的 Reactive Programming 类库主要有三个,分别是 Akka-Streams ,RxJava 和 Project Reactor。Spring 5 开始支持 Reactive Programming,其底层使用的是 Project Reactor。本篇主要是对 Project Reactor 中的一些点进行学习总结。
Project Reactor
Project Reactor 是一个基于 Java 8 的实现了响应式流规范 (Reactive Streams specification)的响应式库。
Reactor 引入了实现 Publisher 的响应式类 Flux 和 Mono,以及丰富的操作方式。 一个 Flux 对象代表一个包含 0..N 个元素的响应式序列,而一个 Mono 对象代表一个包含零或者一个(0..1)元素的结果。
Flux 和 Mono
Flux 是生产者,即我们上面提到的 Publisher,它代表的是一个包含 0-N 个元素的异步序列,Mono可以看做 Flux 的有一个特例,代表 0-1 个元素,如果不需要生产任何元素,只是需要一个完成任务的信号,可以使用 Mono。
Flux-包含 0-N 个元素的异步序列
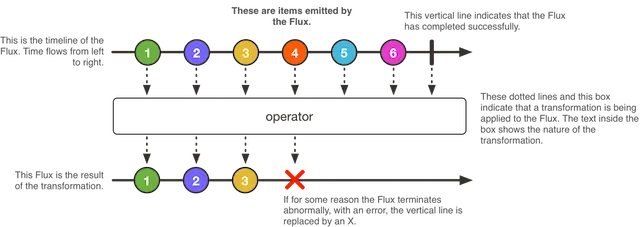
先来看这张图,这里是直接从官方文档上贴过来的。就这张图做下说明,先来关注几个点:
- 从左到右的时间序列轴
- 1-6 为 Flux enitted(发射)的元素
- 上面 6 后面的竖线标识已经成功完成了
- 下面的 1-3 表示转换的结果
- ❌ 表示出现了error,对应的是执行了onError
- operator : 操作符,声明式的可组装的响应式方法,其组装成的链称为“操作链”
那整体来看就是 Flux 产生元数据,通过一系列 operator 操作得到转换结果,正常成功就是 onCompleted,出现错误就是 onError。看下面的一个小例子:
1 | Flux.just("glmapper","leishu").subscribe(new Subscriber<String>() { |
执行结果:
1 | onSubscribe,class reactor.core.publisher.StrictSubscriber |
如果在 onSubscribe 方法中我们不执行 request,则不会有后续任何操作。关于 request 下面看。
Flux
是一个能够发出 0 到 N 个元素的标准的 Publisher ,它会被一个 “error” 或 “completion” 信号终止。因此,一个 Flux 的结果可能是一个 value、completion 或 error。 就像在响应式流规范中规定的那样,这三种类型的信号被翻译为面向下游的 onNext,onComplete和onError方法。
Mono-异步的 0-1 结果
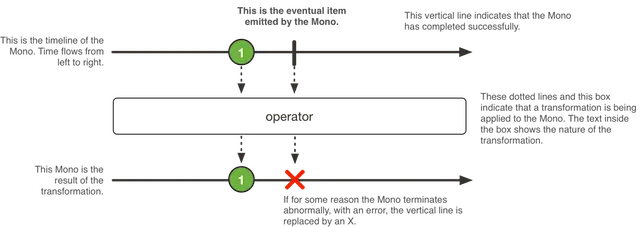
这张图也来自官方文档,和上面 Flux 的区别就是,Mono 最多只能 emitted 一个元素。
1 | Mono.just("glmapper").subscribe(System.out::println); |
小结
通过上面两段小的代码来看,最直观的感受是,Flux 相当于一个 List,Mono 相当于 Optional。其实在编程中所有的结果我们都可以用 List 来 表示,但是当只返回一个或者没有结果时,用 Optional 可能会更精确些。
Optional 相关概念可自行搜索 jdk Optional
另外,Mono 和 Flux 都提供了一些工厂方法,用于创建相关的实例,这里简单罗列一下:
1 | // 可以指定序列中包含的全部元素。创建出来的 Flux |
上面的这些静态方法适合于简单的序列生成,当序列的生成需要复杂的逻辑时,则应该使用 generate() 或 create() 方法。
一些概念
- Operator:Operator 是一系列函数式的便捷操作,可以链式调用。所有函数调用基本都 是 Reactor 的 Operator ,比如 just,map,flatMap,filter 等。
- Processor:上面从 Processor 的接口定义可以看出,它既是一个 Subscriber,又是一个 Publisher;Processor 夹在第一个 Publisher 和最后一个 Subscriber 中间,对数据进行处理。有点类似 stream 里的 map,filter 等方法。具体在数据流转中, Processor 以 Subscriber 的身份订阅 Publisher 接受数据,又以 Publisher 的方式接受其它 Subscriber 的订阅,它从自己订阅的 Publisher 收到数据后,做一些处理,然后转发给订阅它的 Subscriber。
- back pressure:背压。对 MQ 有了解的应该清楚,消息积压一般是在消费端,也就是说生产端只负责生产,并不会关心消费端的消费能力,这样就到导致 pressure 积压在消费端,这个是正向的。从上面对 Reactor 中的一些了解,Subscriber 是主动向 Publisher 请求的,这样当消费端消费的速度没有生产者快时,这些消息还是积压在生产端;这种好处就是生产者可以根据实际情况适当的调整生产消息的速度。
- Hot VS Cold :参考 Hot VS Cold
核心调用过程
Reactor 的核心调用过程大致可以分为图中的几个阶段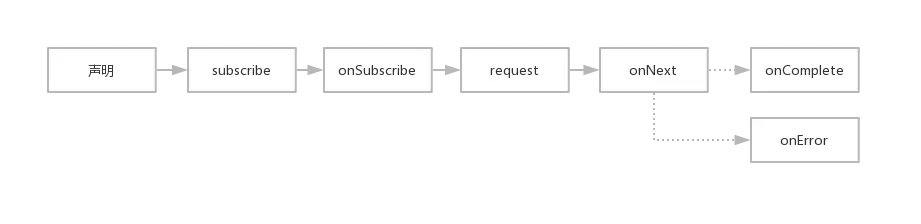
- 声明:无论是使用 just 或者其他什么方式创建反应式流,这个过程都可以称之为声明,因为此时这些代码不会被实际的执行。
- subscribe:当调用 subscribe 时,整个执行过程便进入 subscribe 阶段,经过一系列的调用之后,subscribe 动作会代理给具体的 Flux 来实现。
- onSubscribe:onSubscribe 阶段指的是 Subscriber#onSubscribe 方法被依次调用的阶段。这个阶段会让各 Subscriber 知道 subscribe 方法已被触发,真正的处理流程马上就要开始。
- request:onSubscribe 阶段是表示订阅动作的方式,让各 Subscriber 知悉,准备开始处理数据。当最终的 Subscriber 做好处理数据的准备之后,它便会调用 Subscription 的 request 方法请求数据。
- onNext:通过调用 Subscriber 的 onNext 方法,进行真正的响应式的数据处理。
- onComplete:成功的终端状态,没有进一步的事件将被发送。
- onError:错误的终端状态(和 onComplete 一样,当发生时,后面的将不会在继续执行)。
消息处理
当需要处理 Flux 或 Mono 中的消息时,可以通过 subscribe 方法来添加相应的订阅逻辑。在调用 subscribe 方法时可以指定需要处理的消息类型。可以只处理其中包含的正常消息,也可以同时处理错误消息和完成消息。
通过 subscribe() 方法处理正常和错误消息
1 | Flux.just(1, 2) |
结果:
1 | 1 |
正常的消息处理相对简单。当出现错误时,有多种不同的处理策略:
- 通过 onErrorReturn() 方法返回一个默认值
1
2
3
4Flux.just(1, 2)
.concatWith(Mono.error(new IllegalStateException()))
.onErrorReturn(0)
.subscribe(System.out::println);
结果:
1 | 1 |
- 通过 onErrorResume()方法来根据不同的异常类型来选择要使用的产生元素的流结果:
1
2
3
4
5
6
7
8
9
10Flux.just(1, 2)
.concatWith(Mono.error(new IllegalArgumentException()))
.onErrorResume(e -> {
if (e instanceof IllegalStateException) {
return Mono.just(0);
} else if (e instanceof IllegalArgumentException) {
return Mono.just(-1);
}
return Mono.empty();
}).subscribe(System.out::println);1
2
31
2
-1 - 通过 retry 操作符来进行重试,重试的动作是通过重新订阅序列来实现的。在使用 retry 操作符时可以指定重试的次数。结果:
1
2
3
4Flux.just(1, 2)
.concatWith(Mono.error(new IllegalStateException()))
.retry(1)
.subscribe(System.out::println);1
2
3
4
5
6
7
81
2
1
2
Exception in thread "main" reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.IllegalStateException
Caused by: java.lang.IllegalStateException
at com.glmapper.bridge.boot.reactor.SimpleTest.testFluxSub(SimpleTest.java:75)
at com.glmapper.bridge.boot.reactor.SimpleTest.main(SimpleTest.java:23)调度器 Scheduler
在 Reactor 中,执行模式以及执行过程取决于所使用的 Scheduler,Scheduler 是一个拥有广泛实现类的抽象接口,Schedulers 类提供的静态方法用于达成如下的执行环境:
- 当前线程(Schedulers.immediate())
1
2
3
4
5Schedulers.immediate().schedule(()->{
System.out.println(Thread.currentThread().getName()+"-"+11);
});
// main-11 - 可重用的单线程(Schedulers.single())。注意,这个方法对所有调用者都提供同一个线程来使用, 直到该调度器(Scheduler)被废弃。如果你想使用专一的线程,就对每一个调用使用 Schedulers.newSingle()。
1
2
3
4
5Schedulers.single().schedule(()->{
System.out.println(Thread.currentThread().getName()+"-"+11);
});
// single-1-11 - 弹性线程池(Schedulers.elastic()。它根据需要创建一个线程池,重用空闲线程。线程池如果空闲时间过长 (默认为 60s)就会被废弃。对于 I/O 阻塞的场景比较适用。 Schedulers.elastic() 能够方便地给一个阻塞 的任务分配它自己的线程,从而不会妨碍其他任务和资源。
1
2
3
4
5Schedulers.elastic().schedule(()->{
System.out.println(Thread.currentThread().getName()+"-"+11);
});
// elastic-2-11 - 固定大小线程池(Schedulers.parallel())。所创建线程池的大小与 CPU 个数等同
1
2
3
4
5Schedulers.parallel().schedule(()->{
System.out.println(Thread.currentThread().getName()+"-"+11);
});
// parallel-1-11 - 基于现有的 ExecutorService 创建 Scheduler
1
2
3
4
5
6ExecutorService executorService = Executors.newSingleThreadExecutor();
Schedulers.fromExecutorService(executorService).schedule(()->{
System.out.println(Thread.currentThread().getName()+"-"+11);
});
// pool-4-thread-1-11 - 基于 newXXX 方法来创建调度器
1
2
3
4
5Schedulers.newElastic("test-elastic").schedule(()->{
System.out.println(Thread.currentThread().getName()+"-"+11);
});
// test-elastic-4-11
一些操作符默认会使用一个指定的调度器(通常也允许开发者调整为其他调度器)例如, 通过工厂方法 Flux.interval(Duration.ofMillis(100)) 生成的每 100ms 打点一次的 Flux
1 | Flux<String> intervalResult = Flux.interval(Duration.ofMillis(100), |
结果:
1 | test-1@0 |
publishOn 和 subscribeOn
Reactor 提供了两种在响应式链中调整调度器 Scheduler 的方法:publishOn 和 subscribeOn。 它们都接受一个 Scheduler 作为参数,从而可以改变调度器。但是 publishOn 在链中出现的位置是有讲究的,而 subscribeOn 则无所谓。
- publishOn 的用法和处于订阅链(subscriber chain)中的其他操作符一样。它将上游 信号传给下游,同时执行指定的调度器 Scheduler 的某个工作线程上的回调。 它会 改变后续的操作符的执行所在线程 (直到下一个 publishOn 出现在这个链上)
- subscribeOn 用于订阅(subscription)过程,作用于那个向上的订阅链(发布者在被订阅 时才激活,订阅的传递方向是向上游的)。所以,无论你把 subscribeOn 至于操作链的什么位置, 它都会影响到源头的线程执行环境(context)。 但是,它不会影响到后续的 publishOn,后者仍能够切换其后操作符的线程执行环境。
1 | Flux.create(sink -> { |
结果:
1 | [elastic-2] [single-1] parallel-1 |
上面这段代码使用 create() 方法创建一个新的 Flux 对象,其中包含唯一的元素是当前线程的名称。
接着是两对 publishOn() 和 map()方法,其作用是先切换执行时的调度器,再把当前的线程名称作为前缀添加。
最后通过 subscribeOn()方法来改变流产生时的执行方式。
最内层的线程名字 parallel-1 来自产生流中元素时使用的 Schedulers.parallel()调度器,中间的线程名称 single-1 来自第一个 map 操作之前的 Schedulers.single() 调度器,最外层的线程名字 elastic-2 来自第二个 map 操作之前的 Schedulers.elastic()调度器。
先到这里,剩下的想到再补充…

