SpringBoot 实践系列-Kafka简介&集成SpringBoot
近期在做 SOFA 与 SpringCloud 的集成,希望通过一系列的 DEMO 工程去帮助大家更好的使用 SOFA 和 SpringCloud;同时也希望大家一起来参与共建和 star。
GitHub传送门:spring-cloud-sofastack-samples
Kafka 简介
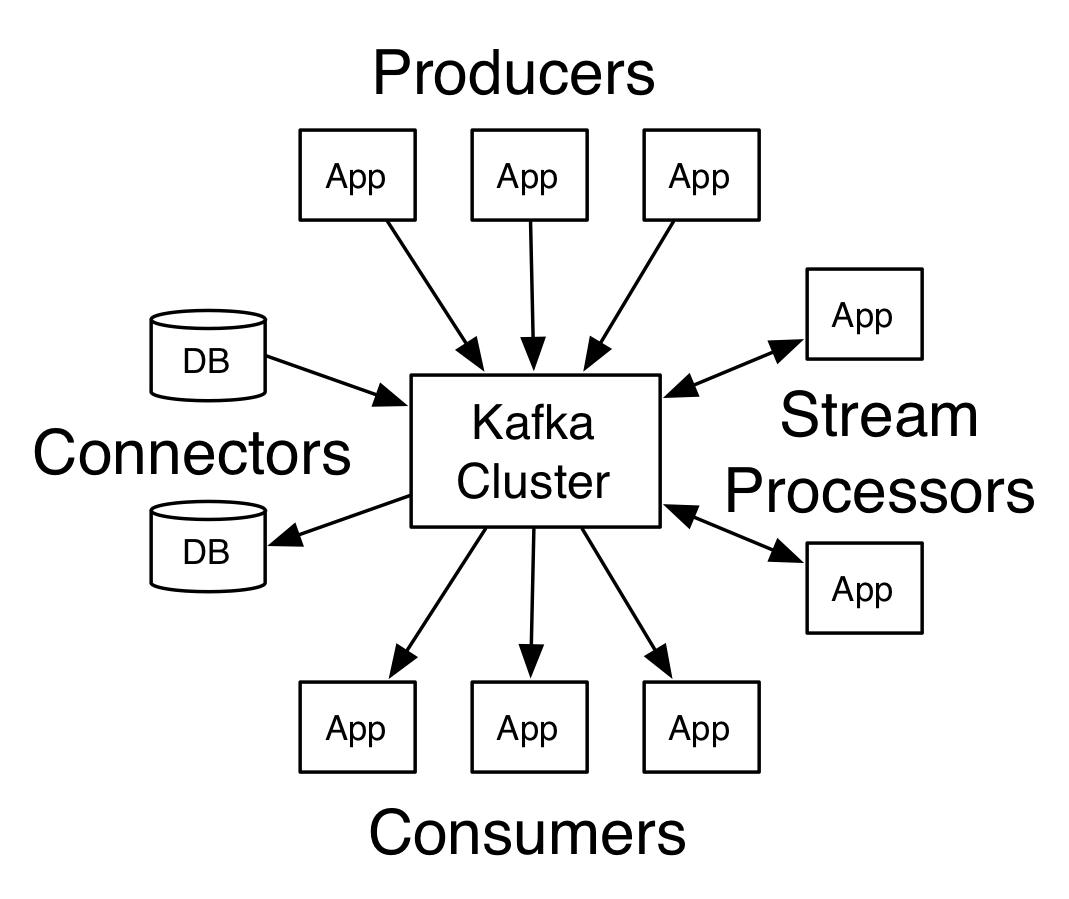
功能提供
Apache Kafka™ 是 一个分布式数据流平台,从官方文档的解释来看,其职能大体如下:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system。发布和订阅数据流,与消息队列或企业级消息系统很像。
- Store streams of records in a fault-tolerant durable way。具有很强容灾性的存储数据流
- Process streams of records as they occur。及时的处理数据流。
作为一个后端司机,大多数情况下都是把 Kafka 作为一个分布式消息队列来使用的,分布式消息队列可以提供应用解耦、流量消峰、消息分发等功能,已经是大型互联网服务架构不可缺少的基础设置了。
基本概念
topic 和 partition
Kafka 对数据提供的核心抽象,topic 是发布的数据流的类别或名称。topic 在 Kafka 中,支持多订阅者; 也就是说,topic 可以有零个、一个或多个消费者订阅写到相应 topic 的数据。对应每一个 topic,Kafka 集群会维护像一个如下这样的分区的日志: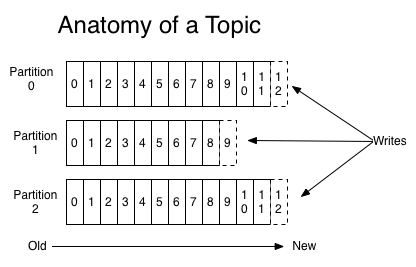
每个 Partition 都是一个有序的、不可变的并且不断被附加的记录序列,也就是一个结构化提交日志(commit log)。为了保证唯一标性识 Partition 中的每个数据记录,Partition 中的记录每个都会被分配一个叫做偏移(offset)顺序的ID号。通过一个可配置的保留期,Kafka 集群会保留所有被发布的数据,不管它们是不是已经被消费者处理。例如,如果保留期设置为两天,则在发布记录后的两天内,数据都可以被消费,之后它将被丢弃以释放空间。 Kafka 的性能是不为因为数据量大小而受影响的,因此长时间存储数据并不成问题。
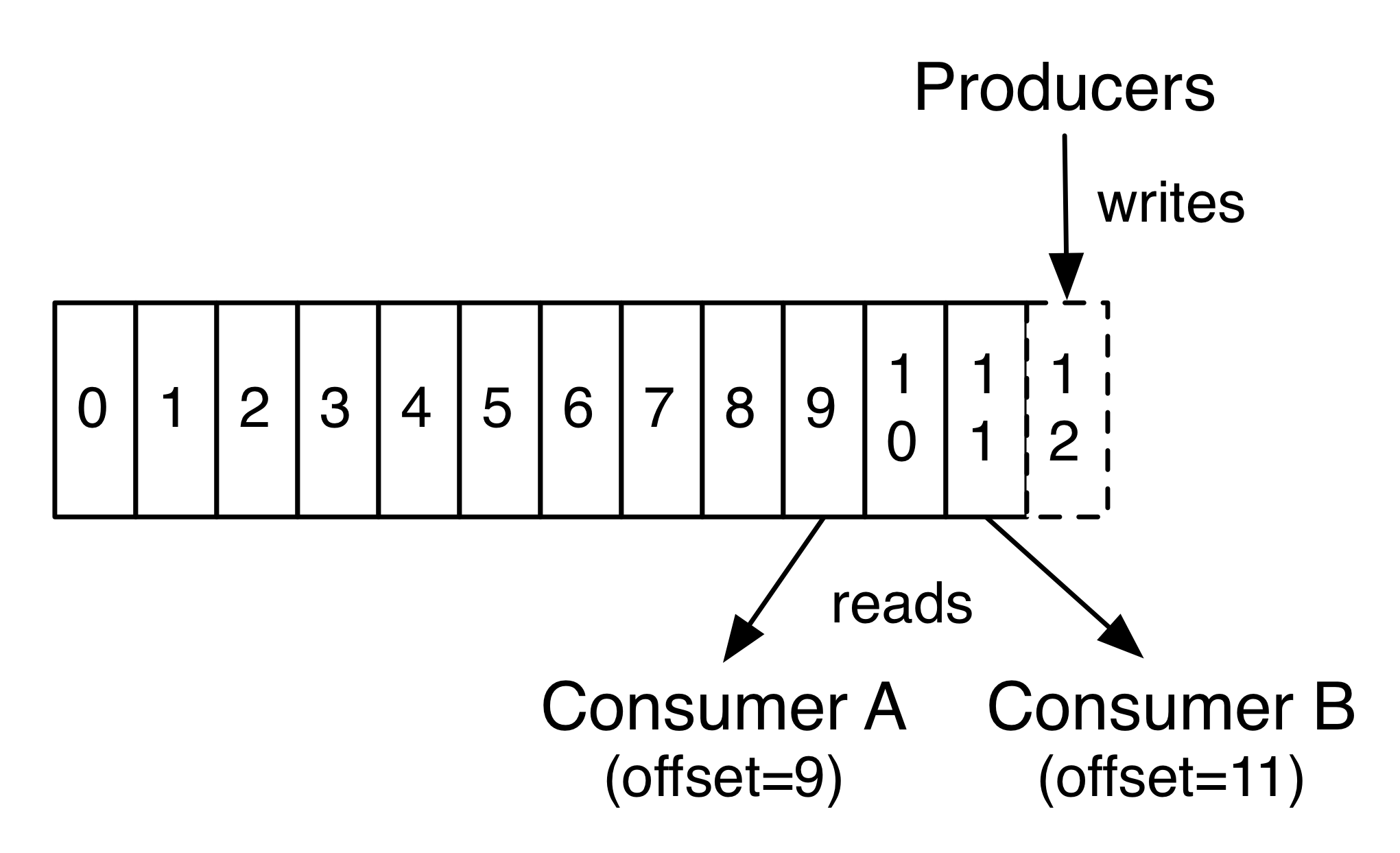
事实上,在每个消费者上保留的唯一元数据是消费者在日志中的偏移位置,这个偏移由消费者控制:通常消费者会在读取记录时线性地提高其偏移值(offset++),但实际上,由于偏移位置由消费者控制,它可以以任何顺序来处理数据记录。 例如,消费者可以重置为较旧的偏移量以重新处理来自过去的数据,或者跳过之前的记录,并从“现在”开始消费。 这种特征的组合意味着 Kafka 消费者非常轻量级,随意的开启和关闭并不会对其他的消费者有大的影响。
日志中的 Partition 有几个目的:
- 保证日志的扩展性,topic 的大小不受单个服务器大小的限制。每个单独的 Partition 大小必须小于托管它的服务器磁盘大小,但 topic 可能有很多 Partition,因此它可以处理任意数量的海量数据。
- 作为并行处理的单位 (知乎-Partition:Kafka可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力)
kafka中的topic为什么要进行分区
原贴:kafka中的topic为什么要进行分区 ,由于不能转载,此处不摘抄原文~
生产者
生产者将数据发布到他们选择的 topic , 生产者负责选择要吧数据分配给 topic 中哪个 Partition。这可以通过循环方式(round-robin)简单地平衡负载,或者可以根据某些语义进行分区(例如基于数据中的某些关键字)来完成。
消费者
消费者们使用消费群组(consumer group )名称来标注自己,几个消费者共享一个 group,每一个发布到 topic 的数据会被传递到每个消费群组(consumer group )中的一个消费者实例。 消费者实例可以在不同的进程中或不同的机器上。
如果所有的消费者实例具有相同的 consumer group,则记录将在所有的消费者实例上有效地负载平衡
如果所有的消费者实例都有不同的 consumer group,那么每个记录将被广播给所有的消费者进程,每个数据都发到了所有的消费者。
上图解释源自《Kafka 官方文档》 介绍:
如上图,一个两个服务器节点的Kafka集群, 托管着4个分区(P0-P3),分为两个消费者群. 消费者群A有2个消费者实例,消费者群B有4个. 然而,更常见的是,我们发现主题具有少量的消费者群,每个消费者群代表一个“逻辑订户”。每个组由许多消费者实例组成,保证可扩展性和容错能力。这可以说是“发布-订阅”语义,但用户是一组消费者而不是单个进程。 在Kafka中实现消费的方式,是通过将日志中的分区均分到消费者实例上,以便每个实例在任何时间都是“相应大小的一块”分区的唯一消费者。维护消费者组成员资格的过程,由卡夫卡协议动态处理。 如果新的实例加入组,他们将从组中的其他成员接管一些分区; 如果一个实例消失,其分区将被分发到剩余的实例。 Kafka仅提供单个分区内的记录的顺序,而不是主题中的不同分区之间的总顺序。 每个分区排序结合按键分区,足以满足大多数应用程序的需求。 但是,如果您需要使用总顺序,则可以通过仅具有一个分区的主题来实现,尽管这仅意味着每个消费者组只有一个消费者进程。
Kafka 作为消息系统
- 队列模式中,消费者池可以从服务器读取,每条记录只会被某一个消费者消费
- 允许在多个消费者实例上分配数据处理,但是一旦数据被消费之后,数据就没有了
- 发布订阅模式中,记录将广播给所有消费者
- 允许将数据广播到多个进程,但无法缩放和扩容,因为每个消息都发送给每个订阅用户
本篇只介绍 Kafka 作为消息队列的一些基本概念,更多介绍请参考官方文档。
Kafka 安装
这里来看下如何安装 kafka,下载地址:https://kafka.apache.org/downloads。本篇使用的版本是 kafka_2.12-1.1.1。
获取包文件
1
> wget http://mirrors.shu.edu.cn/apache/kafka/1.1.1/kafka_2.12-1.1.1.tgz
解压压缩包
1
> tar -zxvf kafka_2.12-1.1.1.tgz
修改配置文件
1
2> cd kafka_2.12-1.1.1/config
> vim server.properties我这里主要修改项包括以下几个:
1
2
3
4
5
6
7
8# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
listeners=PLAINTEXT://192.168.0.1:9092
advertised.listeners=PLAINTEXT://192.168.0.1:9092
# zookeeper 地址,可以多个
zookeeper.connect=192.168.0.6:2181Kafka 服务启动需要依赖 Zookeeper ,所以在配置文件中需要指定 Zookeeper 集群地址。Kafka 自己的安装包中解压之后是包括 Zookeeper 的,可以通过以下的方式来启动一个单节点 Zookeeper 实例:
1
> sh zookeeper-server-start.sh -daemon config/zookeeper.properties
这里我是指定了之前部署的一台ZK机器,所以可以直接将ZK地址指到已部署好的地址。Zookeeper 安装可以参考: Linux 下安装 Zookeeper
通过上述操作,下面就可以直接来启动Kafka 服务了:
1
> sh kafka-server-start.sh config/server.properties
SpringBoot 集成 Kafka
构建一个简单的 Kafka Producer 工具依赖
- 依赖引入
1 | <dependency> |
- producer
为了可以把 Kafka 封装已提供给其他模块使用,大家可以将 Kafka 的生产端工具类使用 SpringBoot 的自动配置机制进行包装,如下:
1 |
|
- KafkaSender
1 | public class KafkaSender { |
- 自动配置
1 | org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ |
工程模块如下:
image-20190306151759441.png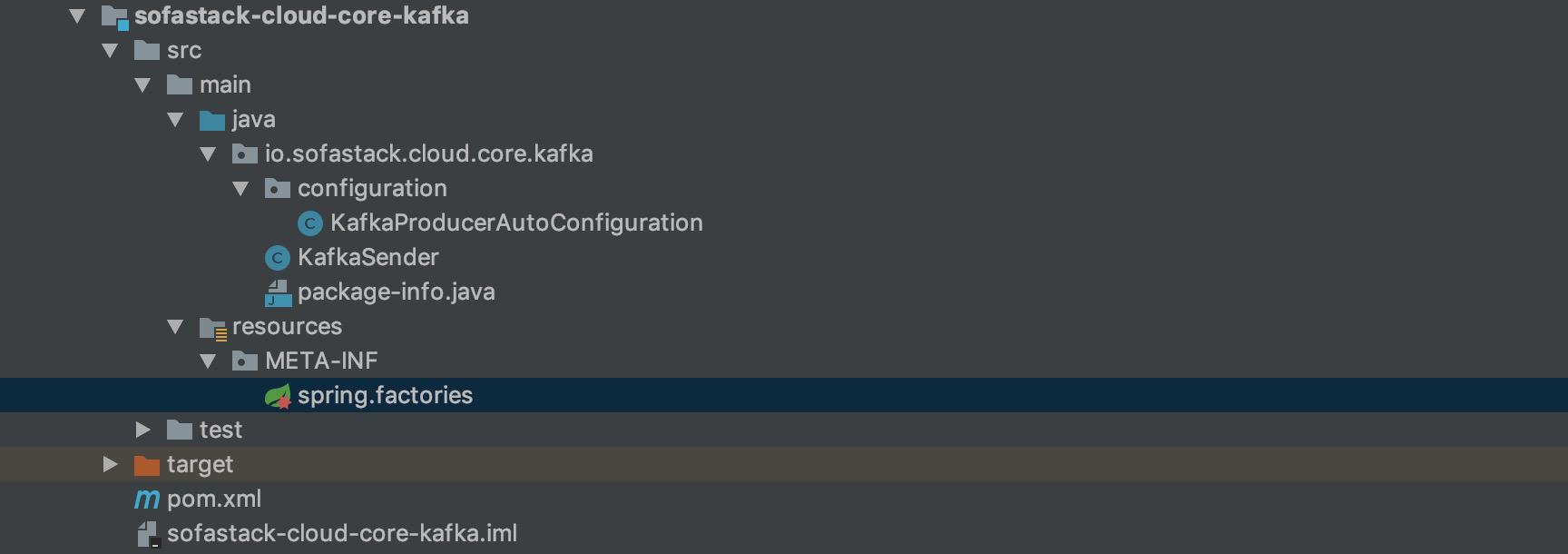
案例测试
在测试工程中引入依赖,这个依赖就是上面工程打包来的:
1 | <dependency> |
- 在 resources 目录下新建 application.properties 配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#============== kafka ===================
# 指定kafka 代理地址,可以多个,这里的192.168.0.1是上面Kafka 启动配置文件中对应的
# 注:网上一些帖子中说 Kafka 这里的配置只能是主机名,不支持 ip,没有验证过,
# 如果您在验证时出现问题,可以尝试本机绑定下 host
spring.kafka.bootstrap-servers= 192.168.0.1:9092
#=============== provider =======================
spring.kafka.producer.retries=0
# 每次批量发送消息的数量
spring.kafka.producer.batch-size=16384
spring.kafka.producer.buffer-memory=33554432
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#=============== consumer =======================
# 指定默认消费者group id
spring.kafka.consumer.group-id=test-consumer-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100ms
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.application.name=kafka-test
logging.path=./logs - 启动类中模拟发送消息
1 |
|
- 编写消费者,在 SpringBoot 工程中,消费者实现非常简单
1 |
|
启动工程后,可以在控制台看下消费者打印的信息:
这里保持应用正常运行,再通过服务端来手动发送消息,看下是当前消费者能够正确监听到对应的 topic 并消费。
1 | > sh kafka-console-producer.sh --broker-list 192.168.0.1:9092 --topic trading |
执行上述命令之后,命令行将会等待输入,这里输入先后输入 glmapper 和 sofa :
然后再看下应用程序控制台输入结果如下:
image-20190306153452565.png
参考
SpringBoot 实践系列-Kafka简介&集成SpringBoot
http://www.glmapper.com/2019/03/07/springboot/springboot-series-kafka-introduction/

