聊一聊 Spring Data JPA 中的那些日常实践
一直以来,团队在使用 ORM 框架上都是比较随意的,一开始是鼓励大家使用 mybatis,主要是期望团队同学可以自
己写写 SQL,不至于写 SQL 手生;但是从实际工作中来看,我们并不会涉及到很多非常复杂的 SQL 语句,这就导致
了大家会消耗相当部分的精力在写一些重复性并且没有什么技术难度的 SQL,对于基于数据库驱动的业务来说,当业务
涉及到的表结构越多时,这种问题就越突出。于是我在项目的脚手架中就提供了 mybatis 和 jpa 两种访问数据库的
方式,但是在随后的一段时间中发现,团队在使用 jpa 来操作数据库上的代码提交几乎为0,而有相当部分的同学则
是引入了 mybatis-plus。
对于这个现象,我没有做过多的干预和询问,但从个人使用体验来说,我觉得可能有两个方面的原因:
- 1、mybatis/mybatis-plus 相较于 JPA 来说更灵活,它是国内开发者发起的,网上资源多,且都是中文。
- 2、JPA 对于一些复杂操作用起来很别扭,网上关于 JPA 的高级用法文档很少且比较凌乱,官网上的介绍也很简单。
也大概看了下网上关于 JPA 和 mybatis/mybatis-plus 家族的区别以及对比文章(推荐知乎这篇:SpringBoot开发使用Mybatis还是Spring Data JPA??,也都各有各的支持者。本篇文档不对比优劣,仅基于自己的项目实践,梳理了关于 JPA 的一些使用方式,这些使用方式主要是针对其默认 CrudRepository 在诸如分页、复合条件查询等方面不足的一些实践使用。
关于 Spring Data 中的 Repository
Repository
Repository 概念是 Spring Data 中的,源码中关于这个接口的注释写的比较清楚,它是一个标记接口,类似与 Java 中的 Serializable 接口差不多含义。那放在 Spring Data 中来解释那就是用于交互数据仓库的接口。它介于业务层和数据层之间,将两者隔离开来,在它不同的实现内部封装了数据查询和存储的逻辑。
Central repository marker interface. Captures the domain type to manage as well as the domain type's id type. General purpose is to hold type information as well as being able to discover interfaces that extend this one during classpath scanning for easy Spring bean creation.
Repository 和 DAO
DAO 是传统 MVC 中 Model 的关键角色,全称是 Data Access Object。DAO 直接负责数据库的存取工作,乍一看两者非常类似,但从架构设计上讲两者有着本质的区别:
- Repository 蕴含着真正的 oo 概念,即一个数据仓库角色,负责所有对象的持久化管理。
- DAO 没有摆脱数据的影子,仍然停留在数据操作的层面上。
Repository 是相对对象而言,DAO 则是相对数据库而言,虽然可能是同一个东西 ,但侧重点不同。
Spring Data JPA
Spring Data JPA 作为 Spring Data 的子集项目,其扩展了 Repository 接口,并提供了一组便于操作数据库的子类。如下图所示:
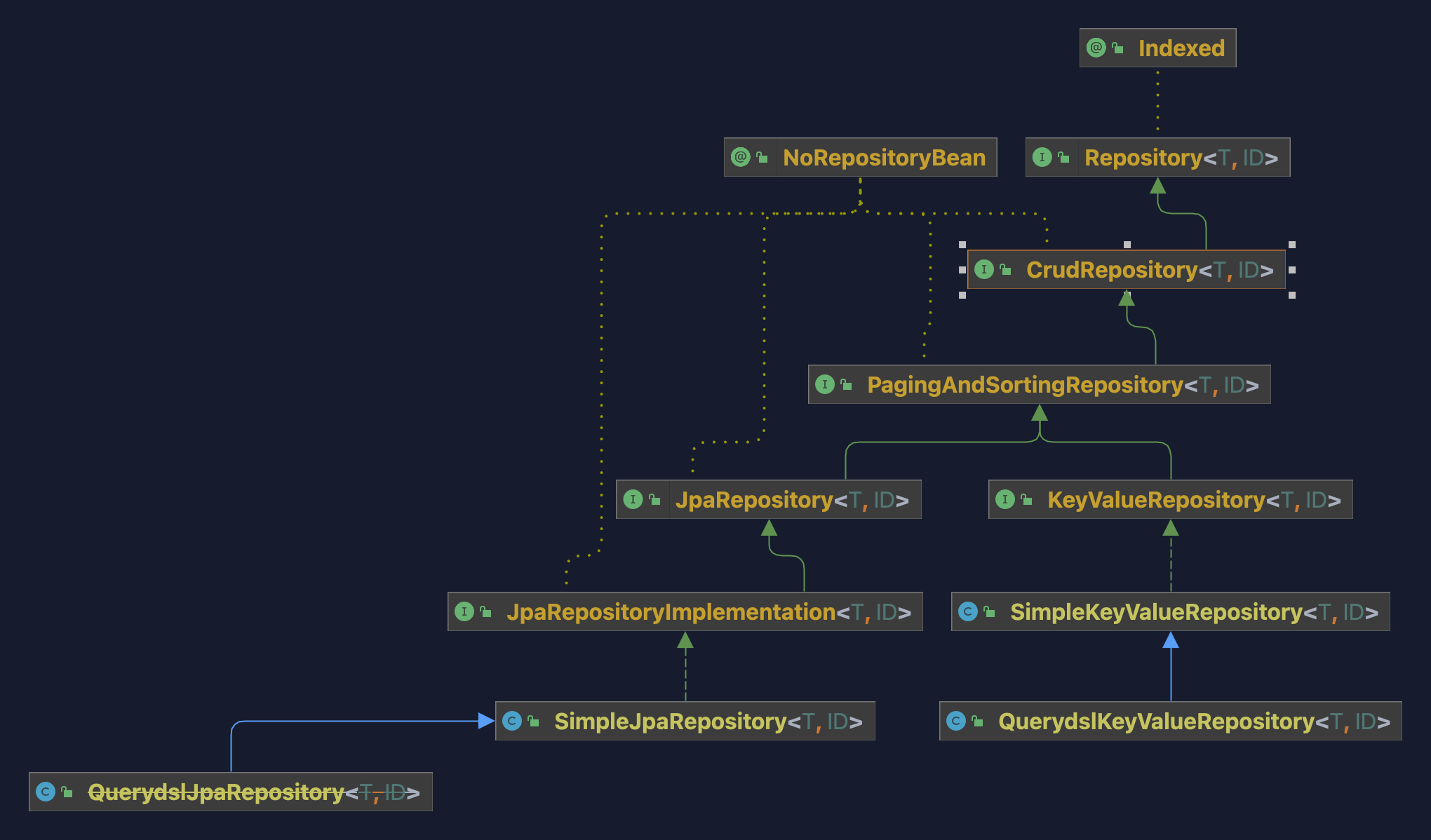
PS: KV-Repository主要是对接 Nosql 部分,这里也放出来提供对比视图
三种 Repository
上面这张图我们主要关注的是 CrudRepository、PagingAndSortingRepository 和 JpaRepository。
CrudRepository:提供最基本的CRUD操作。PagingAndSortingRepository:在CrudRepository的基础上,提供排序和分页能力。JpaRepository:在PagingAndSortingRepository的基础上,进一步提供了查询列表、批量删除、强制同步以及Example查询等能力。
在我们项目中,目前是基于 CrudRepository 接口的,因此大多数情况下,对于基本的分页查询能力从 CrudRepository 的视角是不可感知的,亦或是有同学关注到了这一点,但是对比于 mybaitis-plus 来说,缺少了一些吸引力。
Example 构建动态查询
Example 构建查询主要是基于 QueryByExampleExecutor 接口,QueryByExampleExecutor 接口提供了一组方法,其入参为 Example 对象,通常情况下,可以通过 Example 提供的静态方法结合 ExampleMatcher 来构建 Example。在使用上,根据官方文档的描述来看:
- No support for nested or grouped property constraints, such as
firstname = ?0 or (firstname = ?1 and lastname = ?2),不支持嵌套或分组的属性约束 - Only supports starts/contains/ends/regex matching for strings and exact matching for other property types,只支持字符串 start/contains/ends/regex 匹配和其他属性类型的精确匹配。
下面给出两个常用的基本示例。
OpenTalkUserRepository
1
2
3public interface OpenTalkUserRepository extends CrudRepository<OpenTalkUserEntity,Long>,
QueryByExampleExecutor<OpenTalkUserEntity> {
}按照指定列精确查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14/**
* 按多条件精确匹配查询
*/
public void test_base_dynamic_query_fixed() {
// 构建实体类需要动态查询的条件,按照 sourceFrom 和 verified 进行指定条件值匹配查询
OpenTalkUserEntity user = new OpenTalkUserEntity();
user.setSourceFrom("qq");
user.setVerified("1");
// 注意: 这个 Example 对象是 spring data 的 { @link: org.springframework.data.domain.Example}
Example<OpenTalkUserEntity> example = Example.of(user);
List<OpenTalkUserEntity> list = (List<OpenTalkUserEntity>) repository.findAll(example);
Assert.assertTrue(list.size() > 0);
}按照指定列模糊查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/**
* 按指定字段条件模糊匹配查询
*/
public void test_base_dynamic_query_like() {
OpenTalkUserEntity user = new OpenTalkUserEntity();
user.setEmail("qq");
// 创建一个新的匹配器,默认情况下,probe 中所有的非空属性都匹配。即所有的属性条件用 and 连接
// matchingAny: probe 中所有的非空属性匹配一个即可。即所有的属性条件用or连接
// matchingAll: probe 中所有的非空属性都匹配。即所有的属性条件用and连接
// probe 表示含有对应字段的实例对象
ExampleMatcher matcher = ExampleMatcher.matching();
// 查询 email 中包括 qq 的记录
// 这里指定列名, GenericPropertyMatcher 为 contains
matcher = matcher.withMatcher("email", ExampleMatcher.GenericPropertyMatchers.contains());
Example<OpenTalkUserEntity> example = Example.of(user, matcher);
List<OpenTalkUserEntity> list = (List<OpenTalkUserEntity>) repository.findAll(example);
Assert.assertTrue(list.size() > 0);
}GenericPropertyMatcher包括以下几种类型:类型 解释 ignoreCase忽略大小写 caseSensitive大小敏感 contains包含 xx 同 “like %xx%” endsWith以 xx 结尾 同 “like %xx” startsWith以 xx 开始 同 “like xx%” exact精确匹配 storeDefaultMatching默认规则,效果和 EXACT 相同 regex正则匹配 复杂组合查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/**
* 组合查询,忽略指定列、忽略 null 值、忽略 大小写等
*/
public void test_base_dynamic_multi_condition_query() {
OpenTalkUserEntity user = new OpenTalkUserEntity();
user.setEmail("qq");
user.setId(17L);
ExampleMatcher matcher = ExampleMatcher.matching();
// 查询 email 中包括 qq 的记录
matcher = matcher.withMatcher("email", ExampleMatcher.GenericPropertyMatchers.contains());
// 忽略主键,所以这里对于上面设置 id = 17 这个条件是无用的,返回结构中会包括 id = 17 的记录
matcher = matcher.withIgnorePaths("id");
// 忽略 null 值
matcher = matcher.withIgnoreNullValues();
// 忽略 大小写
matcher = matcher.withIgnoreCase();
Example<OpenTalkUserEntity> example = Example.of(user, matcher);
List<OpenTalkUserEntity> list = (List<OpenTalkUserEntity>) repository.findAll(example);
System.out.println(JSONObject.toJSONString(list));
Assert.assertTrue(list.size() > 0);
}Specification构建动态查询Example只能针对字符串进行条件设置,那如果希望对所有类型支持,可以使用Specification。Specification需要继承JpaSpecificationExecutor接口。和Example的 QueryByExampleExecutor 类型,JpaSpecificationExecutor也同样提供了一组方法,其入参是Specification。Specification中几个概念:Root:查询哪个表(关联查询) = fromCriteriaQuery:查询哪些字段,排序是什么 =组合(order by . where )CriteriaBuilder:条件之间是什么关系,如何生成一个查询条件,每一个查询条件都是什么类型(> between in…) = wherePredicate(Expression): 每一条查询条件的详细描述
下面给出 Specification 的使用示例。
组合条件查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public void test_specification() {
Specification<OpenTalkUserEntity> spec = (root, query, criteriaBuilder) -> {
Path<Integer> type = root.get("verified");
// verified == "1"
Predicate verifiedPredicate = criteriaBuilder.equal(type, "1");
// email like "%qq%"
Path<String> email = root.get("email");
Predicate emailPredicate = criteriaBuilder.like(email, "%qq%");
// and 条件 verified == "1" and email like "%qq%"
Predicate predicate = criteriaBuilder.and(verifiedPredicate, emailPredicate);
return predicate;
};
List<OpenTalkUserEntity> list = this.repository.findAll(spec);
System.out.println(JSONObject.toJSONString(list));
}
使用 Spring Data JPA 的一些实践
分页查询
需要注意的是,不管是 Specification 还是 Example,查询的起始页都是 0,而不是 1。
使用 Specification 的分页查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public void test_specification_combine_page() {
Specification<OpenTalkUserEntity> spec = (root, query, criteriaBuilder) -> {
Path<Integer> type = root.get("verified");
// verified == "1"
Predicate verifiedPredicate = criteriaBuilder.equal(type, "1");
Path<String> email = root.get("email");
// email like "%qq%"
Predicate emailPredicate = criteriaBuilder.like(email, "%qq%");
// and 条件 verified == "1" and email like "%qq%"
Predicate predicate = criteriaBuilder.and(verifiedPredicate, emailPredicate);
return predicate;
};
Sort sort = Sort.by(Sort.Direction.DESC, "createTime");
// 注意这里的起始页为 0
PageRequest pageRequest = PageRequest.of(0, 10, sort);
Page<OpenTalkUserEntity> all = this.repository.findAll(spec, pageRequest);
long total = all.getTotalElements();
List<OpenTalkUserEntity> content = all.getContent();
System.out.println(JSONObject.toJSONString(content));
Assert.assertTrue(total > 0);
}使用 Example 的分页查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public void test_example_combine_page() {
// 构建实体类需要动态查询的条件,按照 sourceFrom 和 verified 进行指定条件值匹配查询
OpenTalkUserEntity user = new OpenTalkUserEntity();
user.setSourceFrom("qq");
user.setVerified("1");
// 注意: 这个 Example 对象是 spring data 的 { @link: org.springframework.data.domain.Example}
Example<OpenTalkUserEntity> example = Example.of(user);
Sort sort = Sort.by(Sort.Direction.DESC, "createTime");
// 注意这里的起始页为 0
PageRequest pageRequest = PageRequest.of(0, 10, sort);
Page<OpenTalkUserEntity> result = repository.findAll(example, pageRequest);
System.out.println(JSONObject.toJSONString(result.getContent()));
Assert.assertTrue(result.getTotalElements() > 0);
}
返回固定列数据
1、定义模型,这里须使用
@lombok.Value注解1
2
3
4
5
6
public class SimpleOpenTalkUserModel implements Serializable {
private String email;
private String verified;
private String sourceFrom;
}2、自定义查询方法
1
2
3
4
5
6
7
8
9/**
* 用户返回指定列的数据
*
* @param email
* @param tClass
* @param <T>
* @return
*/
<T> Optional<T> findCustomByEmail(String email, Class<T> tClass);3、查询数据
1
2
3
4
5
public void test_custom_model() {
Optional<SimpleOpenTalkUserModel> optional = this.repository.findCustomByEmail("test15@qq.com", SimpleOpenTalkUserModel.class);
System.out.println(optional.get());
}
使用 SQL
还是按照上面那个返回自定义对象,这里使用注解的方式来查询
1 | /** |
注意,这里不能使用 nativeQuery = true ,并且 SimpleOpenTalkUserModel 需要提供全参的构造函数。
关联查询
正常的复杂关联查询,完全可以通过使用 nativeQuery = true ,然后编写原生的 SQL 来实现即可。这里不再赘述。
总结
实际上,Spring Data JPA 可以整的花活是非常多的;上面提到的几种案例对于绝大多数业务场景应该是满足的。JPA 提供的封装屏蔽了底层的复杂逻辑,在一定程度上可能会造成性能上的影响,但是对于中小型项目,并且在数据体量不是很大的情况下,JPA 是个不错的选择。
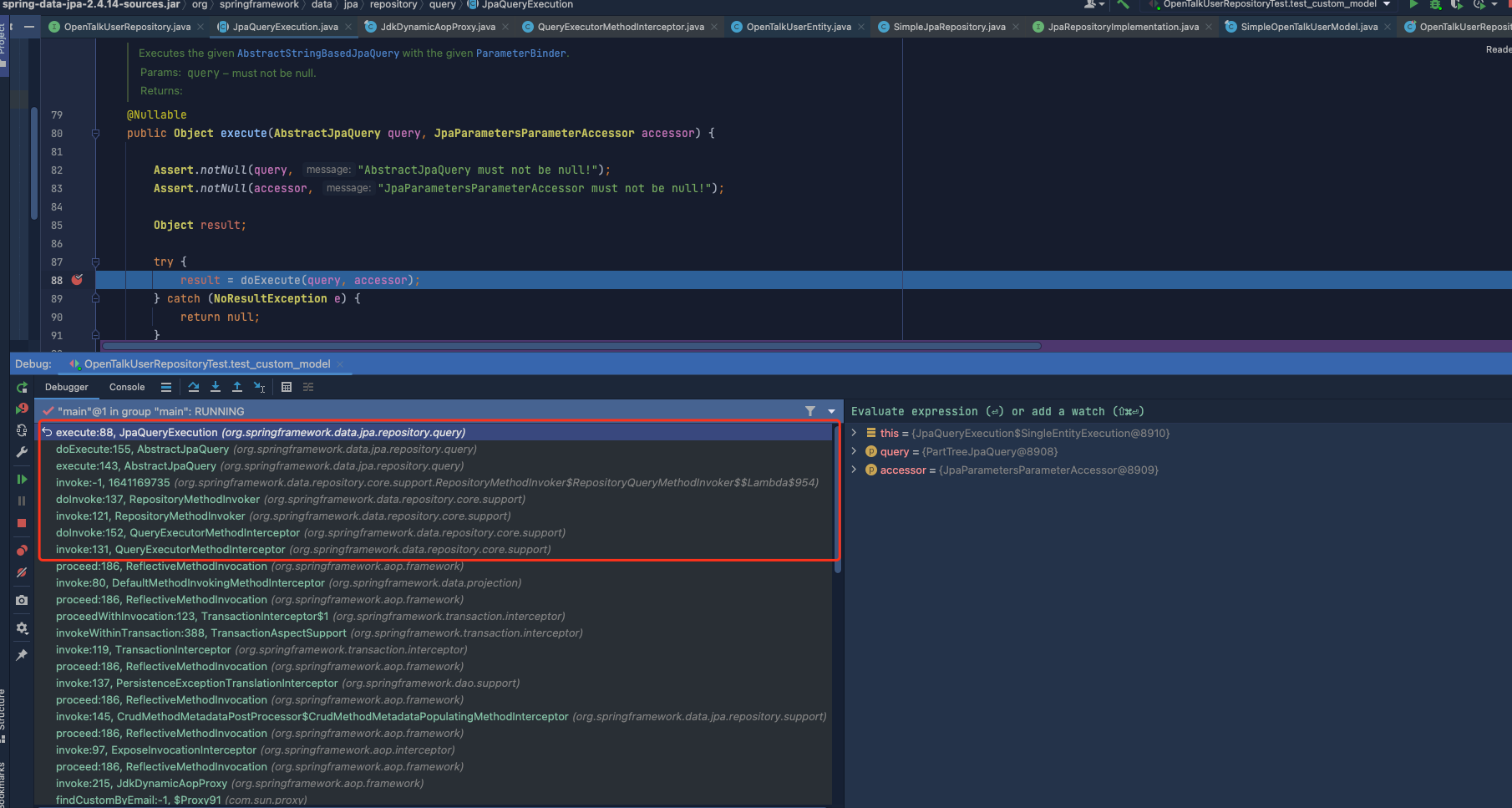
PS: JPA 对于自定义方法,如上面的
findCustomByEmail,刚开始 debug 起来有点摸不到头脑;但是对于 Java 开发者来说,总归绕不过代理这个东西,顺藤摸瓜就找到了。下面补一张图备忘,以便于后续研究其源码时使用。
此代码片段位于 org.springframework.data.jpa.repository.query.JpaQueryExecution 类中
参考
- https://segmentfault.com/a/1190000012346333
- https://zhuanlan.zhihu.com/p/565770887
- https://www.zhihu.com/question/316458408
- https://spring.io/projects/spring-data
- https://spring.io/projects/spring-data-jpa
- https://tuonioooo-notebook.gitbook.io/application-framework/jpapian/spring-data-jpa-quan-mian-jie-xi
聊一聊 Spring Data JPA 中的那些日常实践
http://www.glmapper.com/2023/11/27/springboot/spring-boot-data-jpa-practice/

